Tutorial on Web, XML
Web Overview
World Wide Web (WWW) provides a GUI access to the widespread Internet resources. Technically speaking, WWW is a collection of middleware that operates on top of IP networks (i.e., the Internet). Figure 1 shows this layered view. The purpose of the WWW middleware is to support the growing number of users and applications ranging from entertainment to corporate systems.
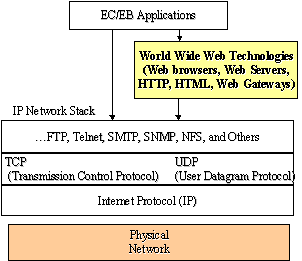
Figure 1: Technical View of Internet and World Wide Web
Like many other (successful) Internet technologies, the WWW middleware is based on a few simple concepts and technologies such as the following (see: Figure 5‑17):
-
Web servers
-
Web browsers
-
Uniform Resource Locator (URL)
-
Hypertext Transfer protocol (HTTP)
-
Hypertext Markup Language (HTML)
-
Web navigation and search tools
-
Gateways to non-Web resources
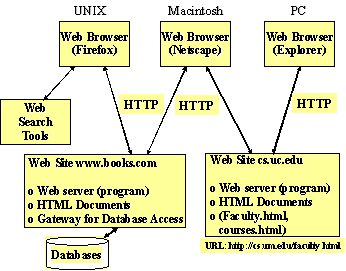
Figure 2: Conceptual View of World Wide Web
Let us briefly review these components and show how they tie with each other through an example.
Web sites provide the content that is accessed by Web users. Web sites are populated and in many cases managed by the content providers. For example, Web sites provide the commercial presence for each of the content providers doing business over the Internet. Conceptually, a Web site is a catalog of information for each content provider over the Web. In reality, a Web site consists of three types of components: a Web server (a program), content files ("Web pages") and/or gateways (programs that access non-Web content). A Web server is a program (technically a server process) that receives calls from Web clients and retrieves Web pages and/or receives information from gateways (we will discuss gateways later). Once again, a Web user views a Web site as a collection of files on a computer, usually a UNIX or Windows NT machine. In many cases, a machine is dedicated/designated as a Web site on which Web accessible contents are stored. As a matter of convention, the entry point to a Web site is a "home page" which advertises the company business. Very much like storefront signs in a shopping mall, the home pages include company logo, fancy artwork for attention, special deals, overviews, pointers to additional information, etc. The large number of Web sites containing a wide range of information that can be navigated and searched transparently by Web users is the main strength of WWW. Figure 5‑17 shows two Web sites -- one for a shoe shop (www.books.com) and the other for a computer science department for a university (cs.um.edu).
Web browsers are the clients that typically use graphical user interfaces to wander through the Web sites. The first GUI browser, Mosaic, was developed at the National Center for Supercomputer Applications at the University of Illinois. Mosaic runs on PC Windows, Macintosh, UNIX and Xterminals. At present, Web browsers are commercially available from Microsoft, Netscape and many other software/freeware providers. These Web browsers provide an intuitive view of information where hyperlinks (links to other text information) appear as underlined items or highlighted text/images. If a user points and clicks on the highlighted text/images, then the Web browser uses HTTP to fetch the requested document from an appropriate Web site. Web browsers are designed to display information prepared in a markup language, known as HTML. We will discuss HTTP and HTML later. Three different browsers are shown in Figure 2. Even though these are different browsers residing on different machines, they all use the same protocol (HTTP) to communicate with the Web servers (HTTP compliance is a basic requirement for Web browsers).
Browsers for many years have been relatively dumb (i.e., they just pass user requests to Web servers and display the results). However, this has changed greatly because of Java, Flash and many other plug-ins to the browsers. For example, Java programs known as Java applets, can run on Java compatible browsers. This has created many interesting possibilities where Java applets are downloaded to the Java enabled browsers where they run producing graphs/charts, invoking multimedia applications, and accessing remote databases.
Uniform Resource Locator (URL) is the basis for locating resources in WWW. A URL consists of a string of characters that uniquely identifies a resource. A user can connect to resources by typing the URL in a browser window or by clicking on a hyperlink that implicitly invokes a URL. Perhaps the best way to explain URLs is through an example. Let us look at the URL "http://cs.um.edu/faculty.html" shown in Figure 2. The "http" in the URL tells the server that an HTTP request is being initiated (if you substitute http with ftp, then an FTP session is initiated). The "cs.um.edu" is the name of the machine running the Web server (this is actually the domain name used by the Internet to locate machines on the Internet). The "/faculty.html" is the name of a file on the machine cs.um.edu. The "html" suffix indicates that this is an HTML file. When this URL is clicked or typed, the browser inititiates a connection to the "cs.um.edu" machine and initiates a "Get" request for the "faculty.html" file. Depending on the type of browser you are using, you can see these requests flying around in an appropriate window spot. Eventually, this document is fetched, transferred to and displayed at the Web browser. You can access any information through the Web by issuing a URL (directly or indirectly). As we will see later, the Web search tools basically return a bunch of URLs in response to a search query. The general format of URL is:
protocol://host:port/path
where
-
protocol represents the protocol to retrieve or send information. Examples of valid protocols are HTTP, FTP, Telnet, Gopher, and NNTP (Network News Transfer Protocol).
-
host is the computer host on which the resource resides.
-
port is an optional port number (this is not needed unless you want to override the HTTP default port, port 80).
-
path is an identification, typically a file name, on the computer host.
Hypertext Markup Language (HTML) is an easy to use language that tags the text files for display at Web browsers. HTML also helps in creation of hypertext links, usually called hyperlinks, that provide a path from one document to another. The hyperlinks contain URLs for the needed resources. The main purpose of HTML is to allow users to flip through Web documents in a manner similar to flipping through a book, magazine or a catalog. The Web site "cs.um.edu" shown in Figure 5‑17 contains two HTML documents: "faculty.html" and "courses.html". HTML documents can imbed text, images, audio, and video.
Hypertext Transfer Protocol (HTTP) is an application-level protocol designed for Web users. It is intended for collaborative, distributed, hypermedia information systems. HTTP uses an extremely simple request/response model that establishes connection with the Web server specified in the URL, retrieves the needed document, and closes the connection. Once the document has been transferred to your Web browser, then the browser takes over. Keep in mind that every time you click on a hyperlink, you are initiating an HTTP session to transfer the needed information to your browser. The Web users shown in Figure 5‑17 access the information stored in the two servers by using the HTTP protocol.
Web navigation and search services are used to search and surf the vast resources available over the "cyberspace". The term cyberspace, as stated previously, was first introduced through a science fiction book by [Gibson 1984] but currently refers to the computer-mediated experiences for visualization, communication, and browsing support. The general search paradigm used is that each search service contains an index of information available on Web sites. This index is almost always created and updated by "spiders" that crawl around the Web sites chasing hyperlinks for different pieces of information. Search engines support key-word and/or subject-oriented browsing through the index. The result of this browsing is a "hit list" of hyperlinks (URLs) that the user can click on to access the needed information. For example, the Web users in Figure 5‑17 can issue a keyword search, say by using a search service for shoe stores in Chicago. This returns a hit list of potential shoe stores that are the content providers. Many search services are currently available on the Web. The best example is Google, of course. Many other search engines such as Yahoo, Lycos and Alta Vista also exist. At present, many of these tools are being integrated with Web pages and Web browsers.
Gateways to non-Web resources are used to bridge the gap between Web browsers and the corporate applications and databases. Web gateways are used for accessing information from heterogeneous data sources (e.g., relational databases, indexed files and legacy information sources) and can be used to handle almost anything that is not designed with an HTML interface. The basic issue is that the Web browsers can display HTML information. These gateways are used to access non-HTML information and convert it to HTML format for display at a Web browser. The gateway programs typically run on Web sites and are invoked by the Web servers. Common Gateway Interface (CGI) is the oldest gateway technology. Since then, many other technologies such as Servlets, JSP, ASP and XSP have appeared. "Relational gateways" that provide access to relational databases from Web browsers are an area of active work.
A Simple Example
Figure 3 illustrates how the Web components can be used for a department store "Clothes-XYZ". This store wants to advertise its products on the Web. (i.e., wants to be a Web content provider). The store first designates a machine, or buys services on a machine, called "clothes.com" as a Web site. It then creates an overview document "overview.html" that tells the potential customers of the product highlights (think of this as the first few pages of a catalog). In addition, several HTML documents on the Web site for different types of clothes (men.html, women.html, kids.html) are created with pictures of clothes, size information etc. (once again think of this as a catalog). We can assume that the overview page has hyperlinks to the other documents (as a matter of fact, it could have hyperlinks to other branches of Clothes-XYZ). In reality, design of the Web pages would require a richer, deeper tree structure design as well as sequential links for alphabetical and keyword searches needed to support the "flipping through" the catalog behavior.
Once HTML documents have been created on the Web server, then an Internet user can browse through them as if he/she is flipping through a catalog. The customers typically supply the URL, directly or indirectly, for the overview (http://clothes.com/overview.html) and then use the hyperlinks to look at different types of clothes. Experienced customers may directly go to the type of clothes needed (e.g., men may directly go to "men.html" document). As shown in Figure 3, the URL consists of three components: the protocol (http), the Web server name (clothes.com), and the needed document (overview.html). HTTP provides the transfer of information between the Web users (the clients) and the Web Servers.
At first, Clothes-XYZ is only using Web to store an electronic catalog. After a customer has browsed through the catalog and has selected an item, he/she calls the store and places an order. Let us say that Clothes-XYZ wants to be more forward looking and wants the customers to purchase the items over the Internet. In this case, a "Purchasing Gateway" software is developed and installed at the Web site. This gateway program gets into action when a user clicks on the "purchase" button on his screen. It prompts the user with a form (HTML supports forms) that the user fills out. The gateway program uses this form information to interact with a purchasing system that processes the purchase (see Figure 3). The purchasing system can be an existing system that is used for traditional purchasing. The role of the gateway is to provide a Web interface to the purchasing system.
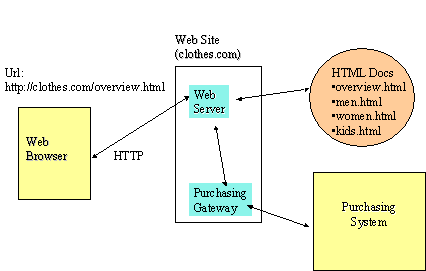
Figure 3: A Simple Web Example
XML Overview
XML is a markup language, similar to HTML, for documents containing structured information. The main limitation of HTML is that it only concentrates on presentation (i.e., headers, highlights, etc) . If you need to specify, for example, the structure of information (i.e., represent customer name and address), then HTML cannot help. Before going into details, let us quickly show a very simple example of XML. The following statements represents an XML document that contains customer name and address:
<CUSTOMER>
<NAME> Joe
</NAME>
<ADDRESS>
NY </ADDRESS>
<AGE> 33 </AGE>
</CUSTOMER>
You can see the striking resemblance between HTML and XML, at least at this simple level (i.e., tags in the format <tag> that are terminated by </tag> ). As we will see, you can develop XML documents that represent customers, orders, bills, airline schedules, TV programs, bank statements, catalogs, etc. by just creating new tags. XML is very popular at present with applications ranging from e-commerce to music.
The term "document" in XML-context refers not only to traditional documents, like articles and books, but also to other XML "data formats" such as e-commerce transactions, mathematical equations, and graphics. XML provides a facility to define tags and the structural relationships between them for documents. There is no preconceived semantics (i.e., meaning) associated with XML because there is no predefined tag set. All of the semantics of an XML document are either defined by the applications that process them or by stylesheets. The XML specification by W3C sets out a set of goals for XML that include ease of use, flexibility, and use over the Internet. A great deal of XML activity exists at present in various areas such as Web (new Web browsers support XML), electronic commerce (XML is being considered as a possible replacement for EDI), data management (e.g., XMI, XML Metadata Interchange, used to exchange models between vendor tools, and CWM, Common Warehouse Metadata, for Oracle and other data warehouses), and publishing (XML is often used in place of SGML because of its “lightness”). According to the W3C, XML:
-
Enables internationalized media-independent electronic publishing
-
Allows industries to define platform-independent protocols for the exchange of data, especially the data of electronic commerce
-
Delivers information to user agents in a form that allows automatic processing after receipt
-
Makes it easier to develop software to handle specialized information distributed over the Web
-
Makes it easy for people to process data using inexpensive software
-
Allows people to display information the way they want it, under style sheet control
-
Makes it easier to provide metadata -- data about information -- that will help people find information and help information producers and consumers find each other
The XML Activity (phase 1), was started by the W3C in June 1996. It culminated in the W3C XML 1.0 Specification (issued February 1998, revised Oct 2000). In the second phase, work proceeded in a number of working groups in parallel. In September 1999, W3C began the third phase, continuing the unfinished work from the second phase and introducing a Working Group on XML Query. Since 1996, the work of several W3C working groups and other standards/industrial bodies has resulted in a “family” of XML standards that include (see Figure 4):
-
Document Type Declarations (DTD) to specify the set of rules for the structure of an XML document. DTDs are used to verify and validate XML documents and are thus central to XML-based e-business exchanges.
-
XSL (eXtensible Stylesheet Language) to display information. XSL supports a basic premise of XML – separation of content from presentation. XSL is also useful to translate one XML description to another.
-
XML query language to support querying of XML data.
-
XML schema to specify the format (e.g., the character lengths) and relationships between XML elements.
-
Other developments such as XML Link, XML signature, and XML Path.
-
Variants of XML for different application areas. Examples are the Wireless Markup Language (WML), Voice Markup Language (VML), Mathematical Markup Languge (MathML), Chemical Markup Language (CML) and others.
Due to the popularity and growth of XML, W3C has started an XML Coordination Group to coordinate the workflow and dependencies between various working Groups. The Group also maintains liaison inside and outside the W3C and gathers and forwards requests for additional requirements to the appropriate WG(s).
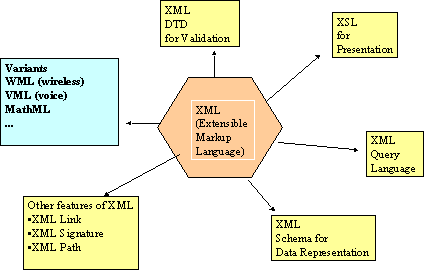
Figure 4: The XML Family